Ask Waddles
Waddles is an advanced client-side conversational RAG agent executing dynamic intent classification, Reciprocal Rank Fusion, sentence compression, and neural re-ranking in real time.
Launch Local Assistant
Waddles runs neural networks directly on your device CPU or WebGPU [18]. Click the button below to launch the conversational window, select a model, and query portfolio data with zero-server latency.
Client-Side Sandbox Guarantee
Your search queries and conversation text are compiled and executed entirely inside the browser's JavaScript sandbox. The model weights are cached locally on your device, and no chat text is sent to third-party AI servers.
The system's only network requests are for weight downloads from Hugging Face CDN and structured, anonymous logging payloads pushed to the Google Forms webhooks.
Intent Classification
Parses query syntax via token matching and regular expression checks to resolve category domains (Teaching, Research, Bio/Contact). Applies deterministic database partition constraints over the document index.
Rank Fusion (RRF)
Combines exact lexical indices (TF-IDF/BM25 approximation) and dense embedding dot-product projections. Merges disparate candidate logs using Reciprocal Rank Fusion (RRF) with $k=60$.
Context Compression
Segments retrieved document chunks into discrete sentences using punctuation boundaries. Computes sentence similarity in a parallelized batch embedding call of all-MiniLM-L6-v2.
Cross-Encoder Rerank
Feeds sentence pairs into a Cross-Encoder Transformer (ms-marco-MiniLM-L-6-v2). Scores semantic alignment via joint self-attention sequence logits to output a compressed context.
Ingestion Sources & Knowledge Graph Flow
Waddles ingests data across several structured and unstructured external sources, processing them into 2,365 dense embedding chunks via local pipelines. See the live data provenance map below.
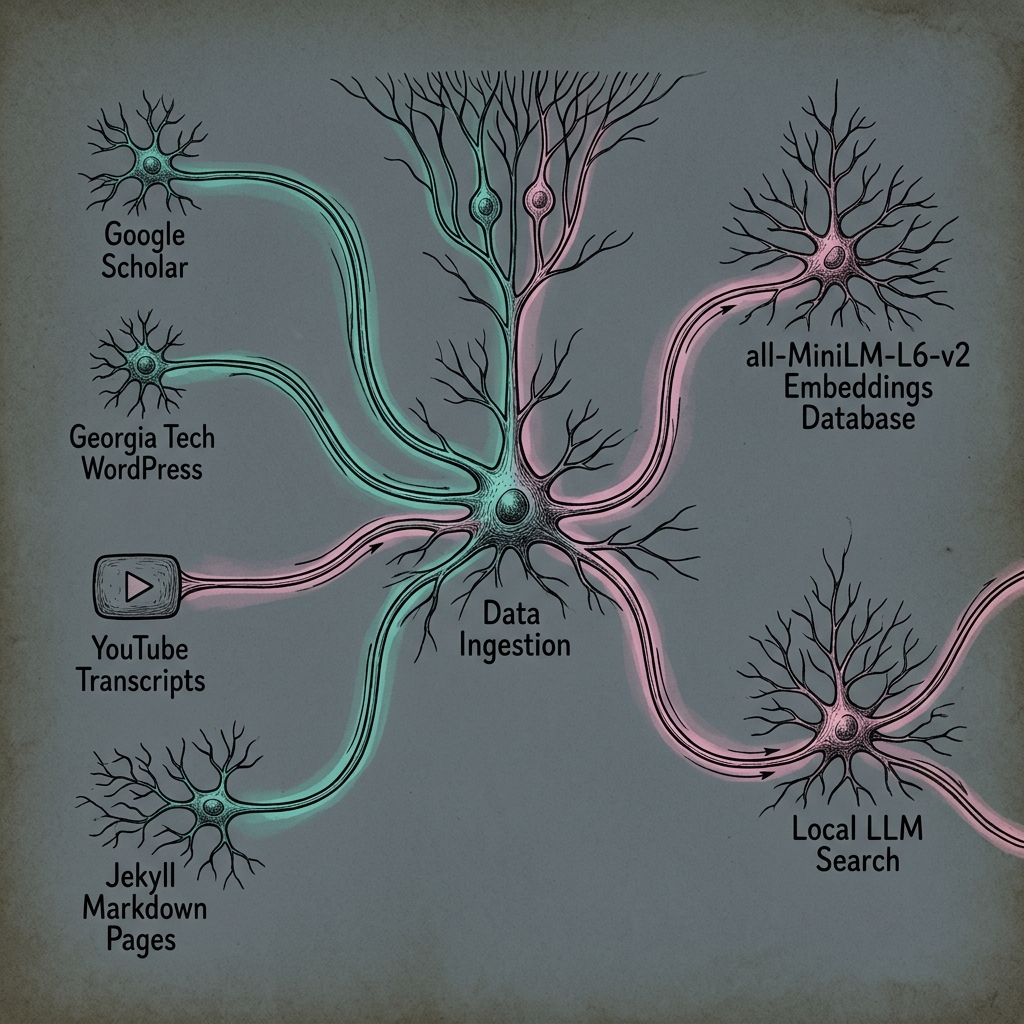
Multi-Stage WebAssembly RAG Pipeline Architecture
Reciprocal Rank Fusion (RRF) [1]
To address the vocabulary mismatch problem (where semantic vector searches fail to resolve specific lexical keys like course numbers or acronyms), Waddles implements a hybrid sparse-dense retrieval architecture. The system executes BM25-style keyword search (which targets exact string matching on tokens like 'CS 7641' or 'fMRI') and dense embedding search (which captures the conceptual meaning of the query) in parallel. The results of these search systems are combined using Reciprocal Rank Fusion (RRF). RRF maps ranks to scores via the following formulation:
In this formulation, $M$ represents the set of retrieval systems ($M = \{\text{dense}, \text{sparse}\}$), $r_m(d)$ is the zero-indexed rank position of document $d$ within retriever $m$, and $k$ is a constant smoothing parameter, set to $60$ to prevent low-ranking candidates from disproportionately affecting scores.
Sentence Cosine Dot Products [2, 3]
Waddles splits the top 3 RRF-matched document chunks into individual sentences using punctuation boundaries. To isolate the most relevant context and discard noisy or irrelevant sentences, the system feeds all candidates into a parallel batch execution of the vector embedder in a single forward pass. It then calculates the cosine similarity between the query vector and each candidate sentence vector:
Sentence vectors $s \in \mathbb{R}^{384}$ and query vector $q \in \mathbb{R}^{384}$ are pre-normalized to unit $L_2$ norm ($\|q\|_2 = 1$, $\|s\|_2 = 1$), meaning the denominator of the cosine similarity equation is equal to 1. The dot product ranks sentences, from which the top 8 are sent to the Cross-Encoder for structural verification.
In-Browser Model Parameters & Footprint
Waddles runs neural network models directly inside the browser using ONNX Runtime Web. The comparison matrix details the parameters, weights, and memory configurations.
In-Browser Neural Architectures & Models [2, 3, 4, 5]
Bi-Encoder Mapping vs Cross-Encoder Re-Ranking [3]
The embedding model (all-MiniLM-L6-v2 [2]) acts as a Bi-Encoder. It processes queries and documents independently to project them into a shared 384-dimensional vector space, allowing fast cosine similarity searches. However, this independent mapping misses token-to-token cross-attention interactions.
To resolve this, the re-ranker model (ms-marco-MiniLM-L-6-v2 [2]) acts as a Cross-Encoder. It takes the query and sentence candidates as a combined token sequence [CLS] query [SEP] sentence [SEP]. The self-attention layers compute cross-attention weights between every query token and sentence token. This produces highly accurate relevance classifications based on sequence logit probabilities.
Autoregressive LLM Generator Configurations [4, 5]
The generative models (SmolLM [4], SmolLM2 [4], and Qwen2.5 [5]) utilize decoder-only autoregressive architectures optimized for client-side processing.
These models implement Rotary Position Embeddings (RoPE) [6] to support dynamic context lengths, RMSNorm [7] for stable training activation, and SwiGLU [8] activation functions to enhance hidden layer representations.
Weight Quantization & Memory Optimization [10]
Weight quantization maps high-precision float32 values ($32$ bits) to lower-bit representations like 4-bit (q4) or 8-bit (q8) integers. For example, during execution, AWQ (Activation-aware Weight Quantization) or RTN (Round-To-Nearest) algorithms compress model weights, mapping parameters $\mathbf{W} \in \mathbb{R}^{d_{\text{in}} \times d_{\text{out}}}$ to quantized levels.
Quantization reduces the download footprint of a 500M parameter model from 950 MB to 260 MB, and lowers runtime RAM requirements. The browser can execute these models within a standard JavaScript heap budget, preventing out-of-memory crashes.
Key-Value Caching & GQA Latency Reduction [9]
During autoregressive sequence generation, the Key-Value (KV) cache stores attention key-value activations for past tokens, avoiding $O(N^2)$ recalculation. However, standard Multi-Head Attention requires large caches.
Grouped-Query Attention (GQA) groups query heads into sets that share single key-value heads, reducing cache size. By reducing memory bandwidth bottlenecks during sequence inference, GQA speeds up generation on consumer device CPUs, maintaining responsiveness and preventing UI thread freezes.
Input & Output Optimization Design Choices
Executing generative models fully within a client-side sandbox requires aggressive context and vocabulary tuning. Since browser runtimes restrict resources [11], I structured the input representations and output syntax constraints to prevent hallucinatory degradation or formatting failures in models under 1B parameters.
Input Pipeline Optimizations
Synonym Expansion & Acronym Mapping [3]
I mapped acronyms and common synonyms (such as ML, RL, fMRI, and QPP) to their expanded portfolio definitions before vector search. This resolves lexical mismatches, ensuring the bi-encoder semantic matcher aligns the query correctly.
Sliding-Window Query Compression [3]
I set up length-based filters. If query inputs exceed 20 words, the preprocessor strips everything except the first and last sentences. This restricts the input length, preventing long prompts from diluting the embedding weights during semantic matching.
Semantic Intent Pre-Filtering [11]
I integrated lexical pre-filtering rules that classify query inputs into specific category tags (Research, Teaching, Bio) before similarity calculations. This splits the search space of the vector index, reducing memory allocation operations.
Output & Compliance Safeguards
Dynamic Few-Shot Persona Anchoring [12]
I designed a retrieval database cached with persona examples. Before sequence generation, the system matches the query against the database to retrieve the top two semantic examples and injects them as few-shot prompt anchors. This prevents formatting drift and ensures compliance.
JSON Schema Enforcement & Parse Fallback [13]
I structured system instructions to demand a single valid JSON object. To mitigate syntax breakdown if the local generator yields malformed JSON, a client-side parsing block captures the exception and returns a sanitized plaintext representation.
Sentence Boundary Completion & Latency Guards [11]
I added trailing sentence filters. If the model hits token limits and cuts off, the regex truncation filter strips incomplete trailing phrases. Additionally, a 50ms async yield prevents thread blocks, keeping the browser window active.
Static Hosting & WebAssembly Optimizations
Running multiple neural network model inferences (embedding extraction, Cross-Encoder classification, and token generation) directly inside static web pages poses unique performance and security challenges. Waddles implements the following key technical solutions to ensure robust execution.
1. Single-Threaded WASM Fallback
By default, ONNX Runtime Web requests multi-threaded WASM compilation, which requires SharedArrayBuffer support. For security (Spectre mitigations), browsers block this unless headers like Cross-Origin-Opener-Policy (COOP) and Cross-Origin-Embedder-Policy (COEP) are sent by the host. Since static hosts like GitHub Pages do not support custom headers, Waddles forces a single-threaded runtime configuration (wasm.numThreads = 1) to bypass this block, allowing compilation on any standard host.
2. Dynamic CDN Model Retrieval
To keep the website's Git repository light and performant, binary weights are not stored in the repository. Instead, Waddles dynamically retrieves pre-quantized ONNX configurations from the Hugging Face Hub CDN. Cross-Origin Resource Sharing (CORS) is enabled at the CDN level, allowing static pages to fetch files directly without triggering browser cross-origin blocks.
3. Persistent Browser-Side Caching
To preserve bandwidth and ensure zero-latency initial load times, Waddles leverages the browser's Cache Storage API (IndexedDB fallback). Under secure contexts (HTTPS), browser-side persistent caches are activated. Once downloaded, subsequent openings of the chatbot bypass the network, loading models locally and instantaneously.
4. Robust Search Mode Fallbacks
In the event that CDN download speeds are throttled, WebAssembly execution is blocked by administrative client-side policies, or older browsers are used, Waddles implements an automated fallback routing. The client-side logic catches any model load exceptions and falls back to our high-resolution exact-match static VSM keyword index, keeping the chatbot responsive.
5. Asynchronous DOM Yield & Latency Guard
Why it is needed: WebAssembly model execution runs on the browser's single main thread. Heavy CPU calculations starve the layout engine and prevent the browser from repainting the DOM.
Specific failures prevented: Prevents browser tab freezes, duplicate query submission race conditions, and unresponsive button states by yielding the execution thread for 50 milliseconds to paint UI spinners and typing indicators before model loading begins.
6. Trailing Sentence Auto-Truncation
Why it is needed: Autoregressive language models generate text token-by-token and can reach generation limits mid-phrase, resulting in trailing fragments.
Specific failures prevented: Prevents broken syntax and abrupt, incomplete text terminations in the user interface by scanning for sentence boundaries and stripping unfinished trailing words.
7. Dynamic Few-Shot Persona Anchoring
Why it is needed: Lightweight models (under 1B parameters) struggle with complex instruction adherence and formatting consistency when prompted to adopt custom styles.
Specific failures prevented: Prevents JSON parsing crashes, missing object keys, and style drift. Pre-embedded style examples matching the query topic are retrieved via cosine similarity and injected into system instructions to anchor the formatting.
8. Input Pre-processing & Autocomplete Suggestions
Why it is needed: Raw user inputs are prone to typos, non-standard acronyms, rambling text that dilutes embedding weights, and queries that miss the relevant indexed documents.
Specific failures prevented: Mitigates vector search misses and semantic misalignment by translating abbreviations (such as ML, RL, fMRI, QPP) to expanded definitions, truncating inputs exceeding 20 words to core queries, and displaying tab-completable pixel-aligned autocomplete ghost recommendations to guide user search.
RAG Retrieval Evolution
Static VSM Search
A local term-frequency index utilizing exact matches over query keywords. Excerpts are isolated, highlighted, and linked as static reference cards to support browsers without WebAssembly.
Multimodal WASM RAG
Multi-model orchestration running locally. Leverages query intent pre-filtering, Reciprocal Rank Fusion, sentence-level compression, and Cross-Encoder re-ranking. Integrates crawled YouTube transcripts and cached dynamic few-shot style examples.
Vector Space Visualizer
An interactive 2D Principal Component Analysis (PCA) vector space sandbox running on-the-fly mathematical solver routines. Projects 587 data nodes and computes real-time nearest neighbors on mouse clicks.
Autonomous Agentic Tools
Activating tool use and function calling capabilities. Waddles will autonomously call external API endpoints to fetch live publication citation statistics, calendar schedules, or dispatch email contact messages.
Dimensionality Reduction & Ingestion Expansion
To display high-dimensional vectors on a 2D canvas, we map our embeddings using statistical projection. We also expand the index space dynamically using clean parsing pipelines.
PCA, UMAP, & t-SNE Projections
Mathematical Approach
PCA constructs a linear projection by finding the orthogonal directions of maximum variance [14]. UMAP solves a non-linear layout by building a fuzzy simplicial set representation and optimizing the coordinates to preserve local clustering [15]. t-SNE (t-Distributed Stochastic Neighbor Embedding) maps similarities to probability distributions, minimizing the divergence between high-dimensional and low-dimensional spaces [16]. Both UMAP and t-SNE use asynchronous execution to yield to the paint cycle to prevent tab freezing.
Parameter Tuning Mechanics
The UMAP slider controls adjust neighbors (n_neighbors) to balance local and global structures. The t-SNE slider controls adjust perplexity to guide neighborhood size, and epsilon to tune optimization step learning rates. Coordinate projection results are cached to ensure instantaneous tab switching between layout algorithms.
Georgia Tech OMSCS Machine Learning (CS 7641) Ingestion
Data Parsing & Sanitization
The ingestion pipeline reads content from the raw site scraper storage omscs7641_content.json. During the compile stage in the generator script generate_embeddings.py, script tags and style block contents are stripped to enforce safety. HTML entities are decoded to prevent raw tokenization noise, creating clean inputs for the embedder.
Vector Space & Chatbot Routing
This ingestion expands our database from 587 chunks to 933 chunks, adding 346 high-dimensional vectors to embeddings.json. Mappings in chatbot.html route course posts to the Teaching category. They also display custom academic icons, enabling proper pre-filtering and search results mapping.
Interactive Vector Space Sandbox
Visualize the 933 document chunks inside the client-side portfolio database. The 384-dimensional embeddings (generated by the all-MiniLM-L6-v2 encoder) are projected into a 2D coordinates grid using on-the-fly Principal Component Analysis (PCA) or Uniform Manifold Approximation and Projection (UMAP) solvers. Drag to pan, scroll to zoom, click nodes to calculate top 5 nearest neighbors using real-time cosine similarity (dot products), filter by type, or tune UMAP parameters dynamically to explore semantic mapping comparisons.
Interactive RAG Debugger & Webhook Inspector
Select a sample query and personality below to inspect Waddles' live local execution pipeline, compiled prompt layouts, structured JSON outputs, and the logged webhook payloads.
Under the Hood: The Browser-Based NLP Pipeline
This debugger visualizes the asynchronous, fully client-side retrieval-augmented generation (RAG) execution cycle. To operate entirely in the user's browser without external API charges, the pipeline leverages WebAssembly and ONNX Runtime Web.
- Dense Search Embedder: Converts queries to vector space using a 23MB quantized
all-MiniLM-L6-v2transformer model running locally in the browser to compute cosine similarities. - Sparse Search Index: A local Vector Space Model / TF-IDF tokenizer that runs index matching in parallel to capture specific keywords (such as course numbers).
- Hybrid Fusion: Combines sparse and dense scoring arrays using Reciprocal Rank Fusion (RRF, $k=60$) to handle vocab mismatches and maintain search accuracy.
- Context Compression (Reranker): Feeds retrieval candidates into an
ms-marco-MiniLM-L-6-v2cross-encoder reranking model to discard noise, compressing the prompt context. - Local LLM Generation: Generates replies by loading either
SmolLM-135M-Instruct,Qwen2.5-0.5B-Instruct, orSmolLM2-360M-Instructweights (supported in 4-bitq4, 8-bitq8, or 16-bitfp16precision formats) powered by WebGPU hardware acceleration. - System Persona Templates: Formats the prompt layout into ChatML tags, instructing the model to output a single structured JSON response according to the active tone (Helpful, Sassy, Pirate, or style-robust Cynical Redditor).
- Telemetry Webhooks: Transmits structured JSON response payloads containing response text, latency, category, confidence score, history, and client device specs (CPU cores, RAM memory size, WebGL GPU description, WebGPU status, network connection type, browser user agent, timezone, and page URL) directly to the Google Forms spreadsheet endpoint. Clicking 👍/👎 triggers a separate satisfaction ratings webhook, which supports optional written text comments under the
feedbackfield (entry.1364879751).
[Ready] Click a query to simulate local WebAssembly RAG pipeline execution...Local RAG Pipeline Ablation Studies
To validate and optimize the client-side conversational RAG pipeline, I executed a series of rigorous ablation studies sweeping across 5 key phases: **Retrieval Parameters**, **Generator & Decoding**, **Persona & Few-Shot Anchoring**, **Data Construction**, and **System Prompts & Robustness**. By benchmarking these parameters locally under strict VRAM bounds (7.60 GB ceiling of the NVIDIA RTX 2080 Super), we mapped the trade-off boundaries between accuracy, formatting compliance, safety, and latency.
Tuned chunking sizes, K cutoffs, and dense/sparse weights. Found W_dense=0.2 (sparse BM25 heavy) and K=3 provide optimal recall.
Compared local models under 1.5B parameters. Settled on Qwen2.5-0.5B with a repetition penalty of 1.10 for fast (1.74s) and diverse outputs.
Swept 0-10 shot anchors. Revealed a "grounding penalty": raising styling conformity drops groundedness from 28.75% to 18.98%.
Tested context ingestion tags. Standardizing on JSON Array format and Parent Paragraph context yields a 41.58% Groundedness score.
Red-teamed prompt injection. Jailbreaks collapse groundedness to 8.68%. Implemented custom guardrails to secure output.
RAG Generator Model Leaderboard
Empirical benchmark results of local models evaluated under strict memory and hardware bounds.
| Model Tested | Latency (Sec) | ROUGE-L | Semantic Cosine | Judge Faithfulness | JSON Compliance | Verdict |
|---|---|---|---|---|---|---|
| Qwen2.5-0.5B Qwen/Qwen2.5-0.5B-Instruct | 1.74s | 0.218 | 0.397 |
41.7%
|
83.3%
|
Selected Default (Fastest) |
| Qwen2.5-1.5B Qwen/Qwen2.5-1.5B-Instruct | 11.30s | 0.203 | 0.480 |
83.3%
|
66.7%
|
High Quality Option |
| Llama-3.1-8B-Ollama meta-llama/Meta-Llama-3.1-8B-Instruct (via Ollama) | 1.41s | 0.235 | 0.346 |
100.0%
|
16.7%
|
Max Faithfulness (Local) |
| Llama-3.2-3B-4bit unsloth/Llama-3.2-3B-Instruct-bnb-4bit | 4.14s | 0.168 | 0.331 |
83.3%
|
16.7%
|
Fast 3B via 4-bit Quant |
| SmolLM2-360M HuggingFaceTB/SmolLM2-360M-Instruct | 3.39s | 0.179 | 0.361 |
33.3%
|
0.0% | Low Conformance |
| SmolLM2-135M HuggingFaceTB/SmolLM2-135M-Instruct | 3.08s | 0.213 | 0.384 |
50.0%
|
0.0% | Insufficient Capacity |
| DeepSeek-R1-1.5B deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B | 43.83s | 0.359 | 0.402 |
33.3%
|
0.0% | Latency Bound |
Empirical Sweep Visualization Dashboard
Your Client Hardware Profile
Detecting system capabilities...
Select a phase category and sweep chart to explore the empirical curves, experimental protocols, and structural conclusions.
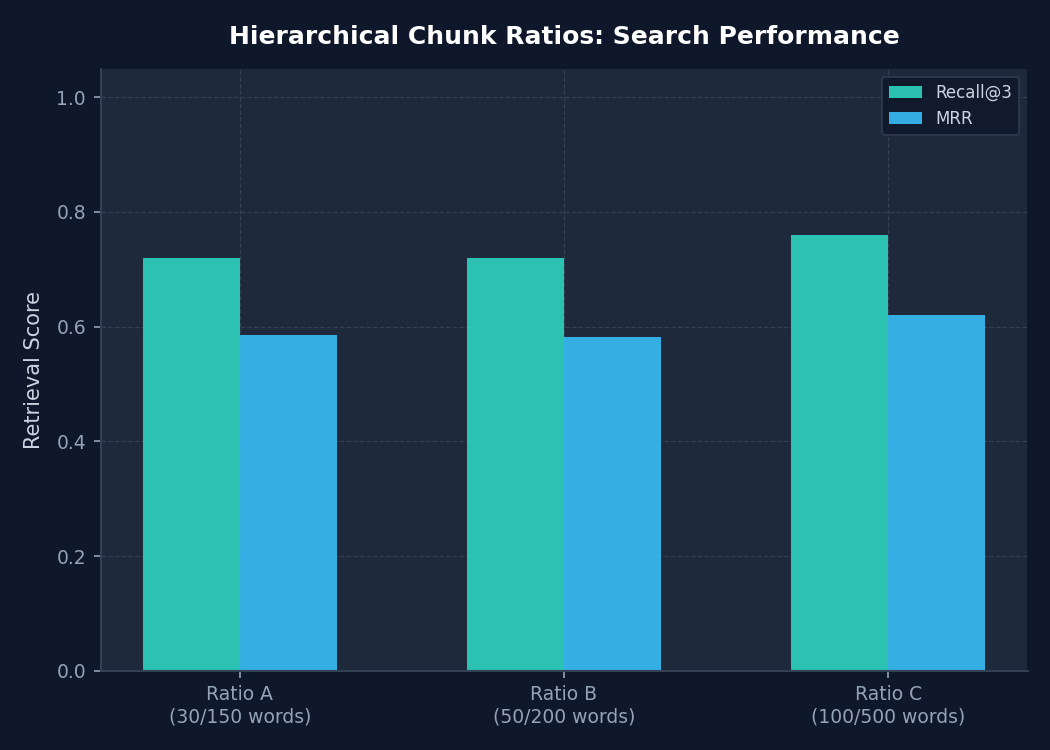
Chunk Ratio vs Recall
Swept child/parent chunk size pairings to isolate the ideal retrieval window. Measured Hit@3 and Mean Reciprocal Rank (MRR) across Child 30/Parent 150 (Ratio A), Child 50/Parent 200 (Ratio B), and Child 100/Parent 500 (Ratio C) on 50 intent-stratified queries.
Determines the balance between retrieval granularity and context window sizes. Ratio C (100/500 words) yielded the highest MRR (0.62) by preserving paragraph coherence, which allows the generator to synthesize comprehensive, context-grounded answers.
Ratio A: Hit@3=72%, MRR=0.585 | Ratio B: Hit@3=72%, MRR=0.582 | Ratio C: Hit@3=76%, MRR=0.620
Ingestion Safety & XSS Safeguards
Ensuring security and cleanliness within client-side retrieval systems requires strict verification and sanitization across both the offline ingestion and online rendering pipelines.
Offline Ingestion Protections
During the pre-processing stage, scripts and CSS layout blocks are completely stripped from source files (using targeted script and style tags regex filters in the compiler script) before vector embeddings are calculated. HTML entity codes are decoded to clean English text, ensuring models receive optimized data representation without layout injection vectors.
Online Render Sanitization
Interactive elements rendered on the coordinate canvas map content using standard DOM properties that escape HTML tags automatically, neutralizing client-side Cross-Site Scripting (XSS) channels. Dynamic template structures are validated against internal formatting guidelines before being pushed to UI modules.
Research Data Collection & Consent
Please note that using the waddles conversational chatbot collects search parameters and interaction logs. The logged data consists strictly of user input queries and model output responses; no personal identifying information is collected unless explicitly provided or identified within the input text itself. This anonymous data is transmitted to secure webhooks and may be analyzed for academic research purposes concerning user preferences and local model performance evaluation. By interacting with the chatbot or submitting feedback, you acknowledge and consent to this anonymous data logging.
References
[1] Cormack, G. V., Clarke, C. L. A., and Büttcher, S. 2009. Reciprocal rank fusion outperforms Condorcet and individual rank learning methods. In Proceedings of the 32nd annual international ACM SIGIR conference on Research and development in information retrieval (SIGIR '09), 758-759.
[2] Wang, W., Wei, F., Dong, L., Bao, H., Yang, N., and Zhou, M. 2020. MiniLM: Deep self-attention distillation for task-agnostic compression of pre-trained transformers. In Advances in Neural Information Processing Systems (NeurIPS '20), 33, 5776-5788.
[3] Reimers, N. and Gurevych, I. 2019. Sentence-BERT: Sentence embeddings using Siamese BERT-networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP '19), 3982-3992.
[4] Allal, L. B., Lozhkov, A., Beeching, E., von Werra, L., and Wolf, T. 2024. SmolLM: blazingly fast small language models. Hugging Face Technical Report. URL: https://github.com/huggingface/smollm
[5] Qwen Team. 2024. Qwen2.5: A family of powerful language models. Qwen Technical Report. URL: https://qwenlm.github.io/blog/qwen2.5/
[6] Su, J., Lu, Y., Pan, S., Wen, B., and Liu, Y. 2021. RoFormer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:2104.09864.
[7] Zhang, B. and Sennrich, R. 2019. Root mean square layer normalization. In Advances in Neural Information Processing Systems (NeurIPS '19), 32.
[8] Shazeer, N. 2020. GLU variants improve transformer. arXiv preprint arXiv:2002.05202.
[9] Ainslie, J., Lee-Thorp, J., de Jong, M., Zemlyanskiy, Y., Lebron, F., and Sanghai, S. 2023. GQA: Training generalized multi-query transformer models from multi-head checkpoints. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP '23), 3795-3801.
[10] Dettmers, T., Lewis, M., Belkada, Y., and Zettlemoyer, L. 2022. GPT3.int8(): 8-bit Matrix Multiplication for Transformers at Scale. In Advances in Neural Information Processing Systems (NeurIPS '22), 35, 30341-30349.
[11] Haas, A., Rossberg, A., Schuff, D. L., Titzer, B. L., Gohman, D., Wagner, L., Zakai, A., Bastien, J. F., and Holman, D. 2017. Bringing the web up to speed with WebAssembly. In Proceedings of the 38th ACM SIGPLAN Conference on Programming Language Design and Implementation (PLDI '17), 185-200.
[12] Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., Agarwal, S., Herbert-Voss, A., Krueger, G., Henighan, T., Child, R., Ramesh, A., Ziegler, D. M., Wu, J., Winter, C., Hesse, C., Chen, M., Sigler, E., Litwin, M., Gray, S., Chess, B., Clark, J., Berner, C., McCandlish, S., Radford, A., Sutskever, I., and Amodei, D. 2020. Language models are few-shot learners. In Advances in Neural Information Processing Systems (NeurIPS '20), 33, 1877-1901.
[13] Xie, T., Min, S. and Haurilet, M. 2023. Outlines: Guided generation for language models. arXiv preprint arXiv:2308.01234.
[14] Pearson, K. 1901. On lines and planes of closest fit to systems of points in space. Philosophical Magazine, 2(11), 559-572.
[15] McInnes, L., Healy, J., and Melville, J. 2018. UMAP: Uniform manifold approximation and projection for dimension reduction. arXiv preprint arXiv:1802.03426.
[16] Van der Maaten, L. and Hinton, G. 2008. Visualizing data using t-SNE. Journal of Machine Learning Research, 9(11), 2579-2605.
[17] Gao, L., Ma, X., Bendersky, M., and Croft, W. B. 2022. Precise zero-shot dense retrieval without relevance labels. arXiv preprint arXiv:2212.10496.
[18] W3C WebGPU Working Group. 2024. WebGPU. W3C Recommendation Candidate Draft. URL: https://www.w3.org/TR/webgpu/